
1. 프로젝트 기획 배경
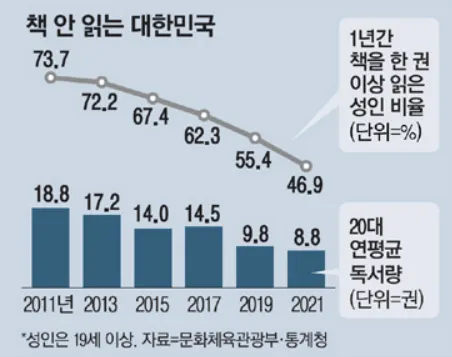

근래에 들어 '한국인의 독서량 감소'와 '젊은 층의 문해력 저하'가 사회적 문제로 떠오르고 있습니다. 책이나 신문과 같은 출판물로 정보를 습득했던 과거와 달리, 오늘날 사람들은 책 이외의 수많은 정보 매체와 미디어로부터 정보를 습득할 수 있게 되며 자연스럽게 독서량이 감소해오고 있습니다.
미디어를 통한 정보 습득과 달리, 독서는 정제되지 않은 정보를 스스로 이해하고 자신의 것으로 습득하는 지적 과정을 거치기 때문에 독서가 문해력과 같은 지적 능력 발달에 매우 중요한 것으로 알려져 있습니다. 따라서 젊은 층의 문해력 저하 문제의 원인이 ‘독서량 감소’에 있다는 의견이 제기되고 있습니다.
이러한 '한국인의 독서량 감소'와 '젊은 층의 문해력 저하'에 대하여, 저희 팀은 독서에 대한 흥미를 높이고 독서를 장려할 수 있는 방안을 제시하는 것이 두 문제의 해결 방안이 될 것이라 생각했습니다.

영화나 드라마처럼 책에도 ost가 필요하다는 Jtbc 멜로디책방 프로그램으로부터 영감을 얻어, 도서 맞춤 음악 추천 시스템이라는 주제를 선정했습니다. 자신이 읽고 있는 책을 입력하면 책과 잘 어울리는 음악을 추천해줌으로써 책의 감정과 내용을 음악 함께 더욱 깊이 음미하는 독서 경험을 제공하고자 합니다. 젊은 층에게 친숙한 음악을 독서와 결합함으로써 독서에 대한 흥미와 즐거움을 더하고, 장기적으로 독서를 장려하는 하나의 문화적 서비스가 될 수 있을 것으로 기대하고 있습니다.

독서에도 OST가 필요하다!
읽고 있는 책 입력 → 어울리는 음악 추천 ⇒ 음악과 함께하는 독서 경험
2. 프로젝트 프로세스
1) 추천 시스템 프로세스
읽고 있는 도서 입력
: 노래를 추천 받고 싶은 도서의 제목 입력
입력한 도서와 노래 간 유사도 분석
: 도서와 노래의 감정적 특성 + 내용 키워드를 기반으로
유사도를 계산하는 Content-based Filtering (CBF) 방식을 사용
유사도가 높은 순서대로 추천 노래 플레이리스트 제공

2) 예시 도서

추천 시스템의 구축 과정과 결과에 대해 설명하기 위해 한 권의 예시 도서를 활용하여 설명하고자 합니다. 본 글에서 활용할 예시 도서는 ‘날씨가 좋으면 찾아가겠어요’입니다.
•
제목 : 날씨가 좋으면 찾아가겠어요
•
저자 : 이도우
•
출판사 : 시공사
•
isbn : 9788952791160
3. 데이터 수집 및 전처리
1) 데이터 수집
도서 설명 데이터

•
도서 데이터를 얻기 위해 Kakao Developers에서 제공하는 Daum 검색 API를 활용했습니다.
•
Daum 검색 API는 Daum에서 웹 문서, 동영상, 이미지, 블로그, 책, 카페를 검색하는 기능을 제공합니다. 도서 검색의 경우 궁금한 도서 제목이나 isbn 번호를 입력하면, 해당 도서를 Daum에 검색했을 때 나오는 도서 정보 웹페이지 내 데이터를 얻을 수 있습니다.
•
저희 팀은 먼저 Daum 검색 API를 이용해 입력 받은 도서의 제목, isbn, 저자, 출판사, Daum 검색 url 등 도서를 식별하기 위한 데이터를 얻었습니다.
•
다음으로 Daum 검색 url에 직접 접속해 도서 정보 웹페이지로부터 책소개, 책속으로, 서평 부분을 크롤링하여 도서 내용에 대해 알 수 있는 데이터를 수집했습니다.
도서 검색 및 도서 정보 웹페이지 예시
도서 데이터 수집 예시
도서 데이터 수집 코드
audio feature
•
audio feature는 노래의 속도, 음정, 박자와 같은 음악적 특징들을 수치화하여 보여주는 데이터입니다. 따라서 노래의 분위기를 파악하기 위한 목적으로 audio feature 데이터를 활용했습니다.
•
Spotify API를 이용해 2020, 2021, 2022, 2023년도에 발매된 음악 트랙의 노래 정보와 audio feature 데이터를 수집하였습니다.
•
노래 정보에는 id (노래 고유 id), Artist (가수 이름), name (노래 제목), url 등이 있습니다.
•
audio feature는 acousticness , danceability , energy , instrumentlness , liveness , loudness , mode , speechiness , tempo , valence , key로 구성됩니다.
audio feature | 의미 |
danceability | 춤 추기에 어울리는 정도, 리듬/비트 규칙성 |
energy | 에너지의 정도, 빠르고 화려하고 노이즈가 많은 음악일수록 값이 큼 |
tempo | 곡의 빠르기, BPM |
key | 음정 |
loudness | 데시벨, 소리의 화려함/큼 정도 |
instrumentalness | ‘악기 소리’의 포함 정도 |
acousticness | 음향적인 정도 (어쿠스틱 장르) |
speechiness | 말하는 정도, 음성 위주인지 혹은 음향 위주인지 |
liveness | 노래의 라이브 정도 |
mode | major(장조), minor(단조) |
valence | 음원의 밝음 정도, 긍정/부정 소리 비율 |
audio feature 수집 예시
노래 : 정국의 “Still With You”
audio feature 수집 과정
0 | 1 | 2 | 3 | 4 | |
0 | {’danceability’: 0.529f 'energy': 0.469, 'key1… | NaN | NaN | NaN | NaN |
1 | {’danceability': 0.726, 'energy': 0.431, 'key1… | NaN | NaN | NaN | NaN |
2 | {'danceability': 0.577f 'energy1: 0.729,
'key1… | {'danceability1: 0.629f 'energy’: 0.585, 'key1… | {’danceability’: 0.596, 'energy': 0.707, ‘key’… | {'danceability’: 0.699, 'energy': 0.78, ’key’… | {'danceability’: 0.517, 'energy': 0.861, ’key’… |
3 | {'danceability1: 0.614, 'energy': 0.934,
'key1… | {'danceability’: 0.592, 'energy’: 0.643,
'key’… | {'danceability’: 0.637, 'energy': 0.69, ’key’… | {'danceability’: 0.683, 'energy': 0.641, ’key’… | {'danceability’: 0.64, 'energy': 0.637, ’key’… |
4 | {’danceability': 0.41, 'energy': 0.611,
’key': … | NaN | NaN | NaN | NaN |
노래 가사
•
앞서 Spotify API에 얻은 노래 정보 데이터를 활용해 노래 가사를 수집하였습니다.
•
url 열을 통해 Spotify 페이지에 접속하면 각각의 노래에 대한 가사를 확인할 수 있습니다. selenium을 이용해 해당 가사를 크롤링해 가사 정보를 수집했습니다.
•
본 프로젝트의 추천 알고리즘은 가사 정보를 필요로 했기 때문에 노래 가사 수집 과정에서 가사가 없는 노래는 제거하였습니다.
트위터 감정 데이터
•
Kaggle에서 제공하는 트위터 감정 데이터를 이용하여 텍스트로부터 감정을 추출하는 모델을 학습시켰습니다.


tweet_id | sentiment | content | |
0 | 1956967341 | empty | @tiffanylue i know i was listenin to bad habi… |
1 | 1956967666 | sadness | Layin n bed with a headache ughhhh...waitin o.… |
2 | 1956967696 | sadness | Funeral ceremony...gloomy friday… |
3 | 1956967789 | enthusiasm | wants to hang out with friends SOON! |
4 | 1956968416 | neutral | @dannycastillo We want to trade with someone W… |
sentiment | |
empty | 공허한 |
sadness | 슬픈 |
enthusiasm | 열광하는 |
neutral | 중립적인 |
worry | 걱정되는 |
surprise | 놀라운 |
love | 사랑 |
fun | 재미있는 |
hate | 싫어하는 |
happiness | 행복한 |
boredom | 지루한 |
relief | 안정된 |
anger | 화난 |
•
데이터는 tweet_id , sentiment , content라는 세 개의 열로 구성되어 있으며 sentiment는 11개의 감정으로 이루어져 있습니다.
◦
empty : 공허한
◦
sadness : 슬픈
◦
enthusiasm : 열광하는
◦
neutral : 중립적인
◦
worry : 걱정되는
◦
surprise : 놀라운
◦
love : 사랑
◦
fun : 재미있는
◦
hate : 싫어하는
◦
happiness : 행복한
◦
boredom : 지루한
◦
relief : 안정된
◦
anger : 화난
2) 데이터 전처리
도서 설명 데이터
•
도서의 감정적 특성 + 내용 키워드 정보를 얻기 위해
도서 내용 설명 text 데이터에 대하여 텍스트 전처리 과정을 진행했습니다.
•
도서 텍스트 전처리 과정
책소개, 책속으로, 서평 3가지 text에 대하여
→ 한글 text를 영어 text로 번역
→ 불용어 처리
→ 토큰화 + 품사 태깅
→ 표제어 추출
<최종 도서 text 데이터>
책소개, 책속으로, 서평 3가지 text를 하나의 text 통합한 후
텍스트 전처리 과정을 거친 상태의 text 데이터
텍스트 전처리란?
도서 텍스트 전처리 결과
텍스트 전처리 코드
audio feature
•
현재 노래 데이터는 앨범을 기준으로, 앨범에 들어있는 각 track 노래들의 정보가 하나의 열에 dictionary 형태로 저장되어 있는 상태입니다. 따라서 각 노래가 하나의 행을 이루고, 노래에 대한 정보가 열에 오도록 dataframe 새롭게 생성합니다.
•
또한 도서에 대한 추천곡으로 적절하지 않을 것이라 판단된 ‘힙합’ 장르의 노래를 제외했습니다.
<전체 노래 데이터>
•
name : 노래 제목
•
track_number : 앨범 내 트랙 순서
•
id : 노래의 id
•
url : 노래 정보가 있는 url (가사 데이터를 수집하기 위해)
•
audio_features : 곡의 audio_features
audio feature 전처리 결과
danceability | energy | key | loudness | mode | speechiness | acousticness | instrumentalness | liveness | valence | tempo | |
0 | 0.529 | 0.469 | 1.0 | -6.967 | 0.0 | 0.0358 | 0.08990 | 0.000015 | 0.8310 | 0.344 | 87.864 |
1 | 0.726 | 0.431 | 8.0 | -8.765 | 0.0 | 0.1350 | 0.73100 | 0.000000 | 0.6960 | 0.348 | 144.026 |
2 | 0.577 | 0.729 | 7.0 | -7.113 | 1.0 | 0.2210 | 0.39400 | 0.000156 | 0.1440 | 0.692 | 180.065 |
3 | 0.629 | 0.585 | 9.0 | -7.969 | 1.0 | 0.0572 | 0.43000 | 0.000000 | 0.3570 | 0.296 | 81.973 |
4 | 0.596 | 0.707 | 1.0 | -6.825 | 1.0 | 0.0490 | 0.11100 | 0.000000 | 0.0926 | 0.262 | 133.858 |
노래 가사
•
노래 가사 text 데이터의 경우 텍스트 분석을 용이하게 하기 위해 모든 언어를 영어로 번역하였습니다. 번역은 Google 에서 제공하는 Google Translator API를 사용했습니다.
•
반복이 많은 전체 가사 데이터를 그대로 모델에 반영하지 않고, 텍스트 요약을 통해서 비교적 중요한 정보만 반영하기 위해 T5 모델을 통한 텍스트 요약을 진행했습니다.
•
이때 무의미한 반복적인 추임새를 중요한 정보로 잘못 판단하는 경우가 다수 발견되었습니다. 따라 해당 가사들에 대해선 가사 요약 전 무의미한 반복 부분을 제거하는 전처리 과정을 먼저 진행한 후 다시 요약해주는 과정을 거쳤습니다. 가사 전처리는 정규식 패턴을 활용하여 이상치를 탐지하고, 단어 분리를 통하여 요약에 도움이 되지 않는 반복 표현을 제거하는 방식으로 진행했습니다.
•
노래 가사 전처리 과정
노래 가사 text
→ 영어로 번역
→ 텍스트 요약
→ 가사 전처리가 필요한 가사들 확인
→ 해당 가사들에 대하여 전처리 후 재요약
T5 (Text-to-Text Transfer Transformer)란?
T5 모델 텍스트 요약 코드
가사 전처리 코드
트위터 감정 데이터
•
tweet_emotion 데이터를 이용해 감정 모델을 구축합니다. SVM모델로 ①content + ②sentiment의 관계를 학습시키기 위해 텍스트 전처리와 라벨링을 진행했습니다.
•
트위터 감정 데이터의 경우 sentiment별로 태깅된 content의 수가 매우 차이가 나며, 이로 인해 데이터가 부족한 sentiment의 경우 인식의 정확도가 떨어지는 문제가 발생했습니다. 따라서 학습 데이터의 수를 더 충분히 확보하기 위해 태깅된 content가 적은 sentiment에 대한 data argumentation(데이터 증강) 과정을 진행했습니다.
•
감정 데이터 전처리 과정
sentiment 열을 라벨링
→ content에 대해 전처리
→ text data argumentation
트위터 감정 데이터, 도서 text와 노래 가사에는 같은 감정 모델을 사용합니다.
같은 모델을 사용하기 위해서는 모델에 들어가는 input의 형태가 같아야 합니다. 따라서 트위터 감정 데이터에서 text를 토큰화 할 때 사용한 방식(tf-idf)을 동일하게 사용했습니다.
텍스트 전처리 코드
sentiment 열 라벨링 코드
text data argumentation 과정
text data argumentation 전처리 후
4. 모델링
1) 감정적 특성 유사도 분석
Audio feature Clustering
•
text에서 추출한 감정과 노래의 분위기를 matching하기 위해 Audio feature값을 기준으로 노래의 mood를 clustering하는 군집화 과정을 수행했습니다.
•
군집화 알고리즘으로는 가장 일반적으로 사용되는 k-means clustering을 사용했습니다.
•
Audio feature clustering 과정
Audio feature 변수 Scaling + PCA
→ 최적의 k값 결정 : Elbow Method
→ k=6에서 clustering 수행
→ 결과로 생성된 6가지 mood의 노래 cluster에 대하여
text에서 추출한 sentiment 항목과 matching
•
노래 mood와 text의 sentiment matching 결과
Cluster 번호 | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 |
노래의 분위기 특징 | 신남 여유로움 박자감 | 의지 극복 강인함 자신감 | 슬픈 어두운 | 박자 타면서 편하게 들을 수 있는 | 어두운 분위기지만 에너지가 느껴지는 | 힘들 때 들으면 좋을 chill한 |
노래 mood | Rhythmical (energetic) | Powerful (determined) | Sorrowful (depressing) | Chill | Bittersweet (melancholic) | Comforting |
감정 matching | happiness, fun, enthusiasm | hate, anger | sadness, empty | relief | worry | boredom |
※ love가 1순위로 나온 경우, (happiness, fun, enthusiasm)와 (sadness, empty) 중 더 순위가 높은 것을 기준으로 happy love 인 경우 → Cluster 1로, sad love인 경우 → Cluster 3으로 분류했습니다.
k-means clustering
Audio feature clustering 결과
Audio feature clustering 코드
Audio feature 감정 추출 모델
•
k-means clustering을 이용해 분류된 Cluster 데이터를 이용해 audio feature를 재학습시킵니다.
•
각각의 클러스터와 매칭되는 sentiment가 모델의 target값이 됩니다.
클러스터와 매칭되는 sentiment는 여러 개가 존재할 수 도 있습니다.
예를 들어, Cluster 4의 경우 ‘worry’라는 하나의 sentiment와 매칭되지만 Cluster 1의 경우 ‘enthusiasm’, ’love’, ’fun’, ’happiness’라는 여러 개의 sentiment와 매칭됩니다.
따라서 multi label classification 을 이용해 audio feature를 학습시켜야 합니다.
→ 이번 프로젝트에서는 새로운 모델을 만들어 사용합니다.
•
Custom 모델 학습 과정
클러스터링으로 분류된 audio feature 데이터
→ 각각의 Cluster에 sentiment 매칭
→ sentiment에 대하여 multi-label encoding을 수행
→ Custom 모델 생성
→ ①audio feature + ②인코딩된 sentiment를 학습 데이터로 사용해 모델 학습
•
feature : audio feature
•
target : 인코딩된 sentiment
→ 각각의 sentiment가 나올 확률 값을 output으로 도출
학습 데이터 셋 구축
Custom 모델 생성
모델 학습 및 예측 진행
전체 audio feature에 대한 확률 값 도출
empty | sadness | enthusiasm | worry | love | fun | hate | happiness | boredom | relief | anger | |
0 | 2.911795e-04 | 4.020837e-04 | 0.000723 | 1.000000 | 0.000268 | 0.000786 | 0.000016 | 0.000905 | 0.000226 | 0.000030 | 0.000021 |
1 | 4.655535e-05 | 5308059e-05 | 0.002717 | 0.000437 | 0.000715 | 0.002430 | 0.001243 | 0.002587 | 0.999995 | 0.000113 | 0.001054 |
2 | 6.876502e-04 | 9.59205 3e-04 | 0.000324 | 0.000625 | 0.000448 | 0.000291 | 0.000311 | 0.000333 | 0.000342 | 1.000000 | 0.000254 |
3 | 1.522953e-03 | 2.080173e-03 | 0.000245 | 0.000927 | 0.001087 | 0.000204 | 0.000420 | 0.000249 | 0.000339 | 0.999903 | 0.000401 |
4 | 9.784889e-04 | 9201588e-04 | 0.000283 | 0.000440 | 0.000199 | 0.000349 | 1.000000 | 0.000242 | 0.000417 | 0.000897 | 1.000000 |
텍스트 감정 추출 모델
•
노래 가사와 키워드 텍스트에 대해 감정을 추출하기 위해 트위터 감정 데이터를 기반으로 SVM 모델을 학습시켰습니다.
•
SVM 모델 학습 과정
text data argument를 진행한 content 데이터
라벨링 과정을 거친 sentiment 데이터
→ TF-IDF 기반 임베딩으로 DTM 생성
→ ①DTM + ②sentiment를 학습 데이터로 사용해 SVM 모델 학습
•
feature : content
•
target : sentiment
→ 각각의 sentiment가 나올 확률 값을 output으로 도출
학습 데이터 셋 구축
SVM 모델 학습
별도의 테스트 셋을 통한 학습 결과 학인
감정적 특성 유사도 분석
노래 - 도서 감정적 특성의 유사도 분석은 2가지 측면에서 진행합니다.
도서 text - audio feature, 감정 유사도 분석
모델을 통해 얻은 audio feature 기반 sentiment 확률 값 모델을 통해 얻은 도서 text 기반 sentiment 확률 값→ 두 sentiment 확률 값 벡터의 코사인 유사도를 계산
도서 text - 노래 가사, 감정 유사도 분석
모델을 통해 얻은 노래 가사 기반 sentiment 확률 값 모델을 통해 얻은 도서 text 기반 sentiment 확률 값→ 두 sentiment 확률 값 벡터의 코사인 유사도를 계산
도서 text - audio feature 결과 예시
도서 text - 노래 가사 결과 예시
코사인 유사도란?
2) 내용 유사도 분석
노래 - 도서 내용 유사도 분석은 text 키워드 추출 과정을 통해 진행합니다.
도서 text - 노래 가사, 내용 유사도 분석
도서 text + 노래 가사, 하나의 dataframe으로 통합
TF-IDF 기반 임베딩 : 각 text에 대하여 단어별 중요도를 계산한 DTM 생성
→ text별 단어 TF-IDF값 벡터 간 코사인 유사도를 계산
도서 text - 노래 가사 결과 예시
TF-IDF란?
3) 최종 유사도 분석
도서 - 가사, 3가지 종류의 유사도
① 도서 text - audio feature, 감정 유사도
② 도서 text - 노래 가사, 감정 유사도
③ 도서 text - 노래 가사, 내용 유사도
•
도서 - 노래 간 유사성을 비교하기 위해 총 3가지의 유사도를 계산했습니다.
•
이 3가지 유사도의 가중합을 통한 유사도 값을 기준으로 추천곡 플레이 리스트를 작성합니다.
5. 결과
추천 리스트 결과
날씨가 좋으면 찾아가겠어요
페드르와 이폴리트
젊은 베르테르의 슬픔
어린왕자
•
적절한 추천
날씨가 좋으면 찾아가겠어요 - 가사 중심
페드르와 이폴리트 - AF : 가사 : 키워드 = 0.8 : 0.1 : 0.1
젊은 베르테르의 슬픔 - AF 중심
어린왕자 - 가사 중심
•
부적절한 추천
날씨가 좋으면 찾아가겠어요 - AF 중심
페드르와 이폴리트 - 전반적으로 적절히 추천됨
젊은 베르테르의 슬픔 - 가사 중심
어린왕자 - AF 중심
•
날씨가 좋으면 찾아가겠어요, 페드르와 이폴리트, 젊음 베르테르의 슬픔, 어린왕자에서 4가지 도서를 이용해 3개 유사도에 다양한 가중치 비율에서 추천 성능을 비교해보았습니다.
•
Audio Feature 감정 : 가사 감정 : 가사 키워드 유사도 가중합 비율을 아래과 같이 설정한 경우 전반적으로 가장 적절히 추천되었습니다.
(1) 0.8 : 0.1 : 0.1의 비율 (Audio Feature 기반 유사도를 중심적으로 사용한 경우)
(2) 0 : 0.5 : 0.5의 비율 (가사 기반 유사도만 사용한 경우)
•
최종 추천 시스템은 Audio Feature 기반 유사도를 중심적으로 사용하여 5권을, 가사 기반 유사도를 중점적으로 사용하여 5권을 각각 추천하여, 총 10권의 도서를 추천하는 것으로 확정했습니다.
6. 한계 및 제언
1.
Audio feature 데이터로 mood를 표현하는 것의 한계
: 기대했던 바와 달리 audio feature가 노래의 mood를 명확하게 분류해주지 못했으며, 사람이 들었을 때 느끼는 mood와 audio feature를 기준으로 한 특성 간 괴리가 존재했다는 한계점이 있습니다. 현재 저희의 추천 시스템에선 노래의 mood가 매우 중요한 추천 기준으로 사용되고 있으나, audio feature에 전적으로 의존하여 노래의 mood 정보를 얻고 있기 때문에 audio feature 데이터 자체의 한계점으로 인해 전체 추천 성능이 저하되는 다소 아쉬운 결과를 얻게 되었습니다.
audio feature 외에 노래의 분위기에 대한 정보를 제공할 수 있는 데이터를 추가적으로 활용합니다. 노래에 대해 설명해주는 text 데이터 혹은 이미 Spotify에서 생성된 노래 분위기별 플레이리스트 속 노래 정보 등을 활용할 수 있을 것으로 기대하고 있습니다.2.
감정 추출 모델 학습 데이터 문제
: 추천 모델에 사용된 text의 경우 공식적인 책 소개 글이나 노래 가사입니다.. 이는 구어적이고 정제되지 않은 표현이 많은 트위터 학습 데이터 text 특성과 차이가 존재합니다. 따라서 트위터 text를 학습 데이터를 사용했던 감정 분석 모델을, text의 특성이 다소 다른 추천 모델 input text에 사용했다는 점으로 인해 감정 분석 결과가 정확하지 않은 경우 발생했습니다.
감정 추출 모델 학습을 위한 데이터 셋을 실제 모델이 사용하게 될 text 특성과 유사한 상태의 text 데이터로 사용했다면, 감정 추출의 정확도를 더욱 높일 수 있었을 것이라 생각됩니다.3.
제한적인 입력 도서 장르
: 현재 추천 시스템이 로맨스 장르의 소설에서 가장 좋은 추천 성능을 보이고, 다른 장르의 경우 추천의 신뢰성이 많이 떨어지는 상태입니다. 이는 행복, 슬픔, 사랑 등 비교적 분류하기 명확한 감정이 주된 분위기를 구성하는 로맨스 장르의 특성으로 인한 것으로 보이며, 이는 곧 현재 추천 시스템이 해당 감정들을 제외한 경우 감정 추출 및 반영을 잘 하지 못하고 있는 것이라 할 수 있습니다.
앞선 노래 분위기 분류에서의 한계점과, 감정 추출 모델에서의 한계점을 개선했을 때 발전 가능할 것으로 기대됩니다. 즉 더 다양한 감정에 대한 감정 추출 모델을 생성함으로써 모델이 다룰 수 있는 감정의 범위가 넓어지고, 해당 감정에 적절히 매칭될 수 있는 분위기의 노래를 분류할 수 있다면 더 넓은 범위의 도서 장르에 대한 노래 추천이 가능할 것입니다.책과 음악 데이터를 활용한 책에 어울리는 음악 추천